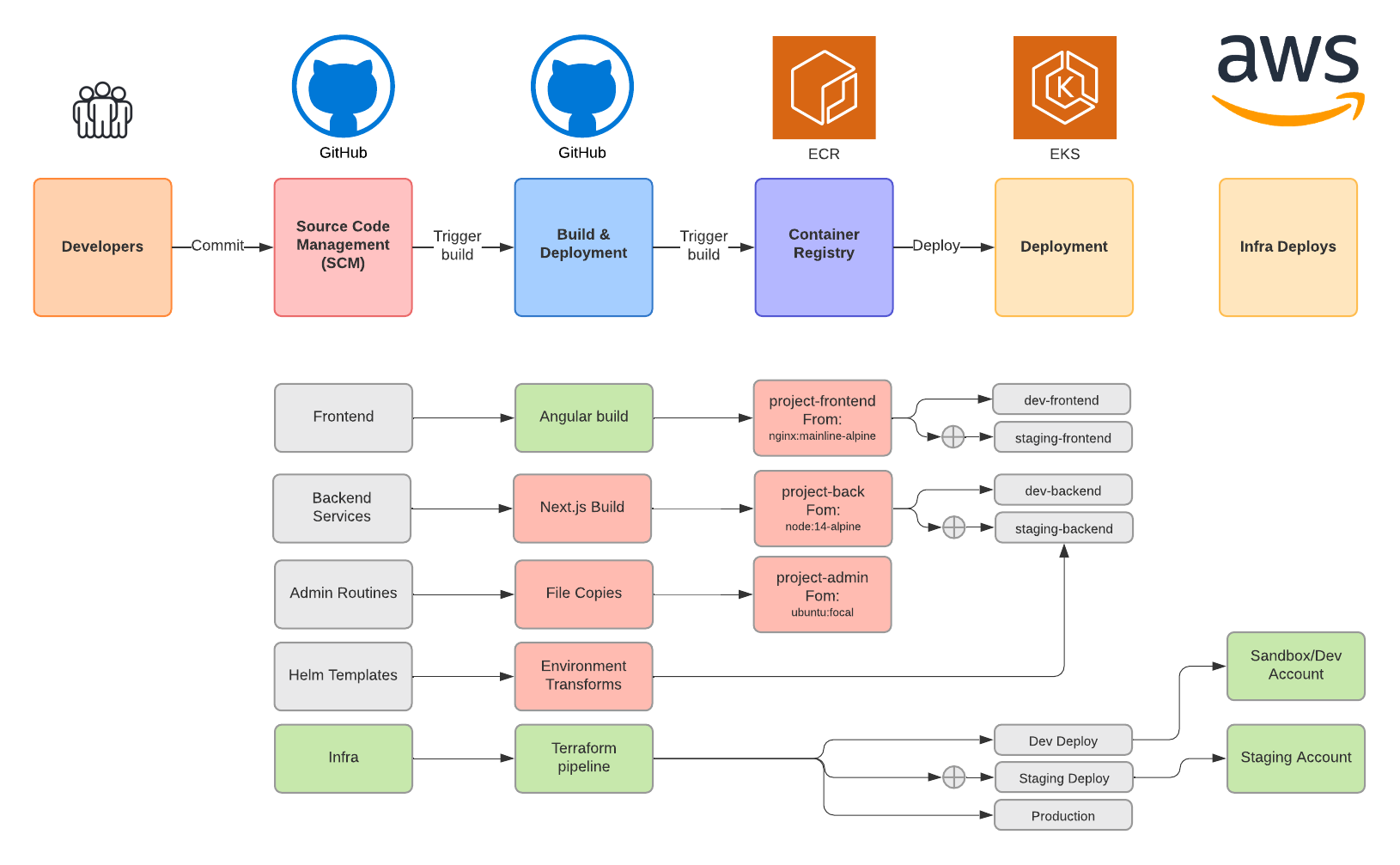
5 Tips for Production-Ready Code
Most code that gets put into production doesn’t start its life that way. In this article, I’d like to help you by giving you 5 tips to help you write code that is ready to be dropped into a variety of hosting scenarios, and allows for easy scaling of load and reliability.
Tip 1: Use the Wisdom from the 12 Factor App Philosophy
Rely on the wisdom from the 12 Factor App.
These are principles on which you should build your application to ensure that they remain deployable and scalable in most situations:
- Codebase - One codebase tracked in revision control, many deploys
- Dependencies - Explicitly declare and isolate dependencies
- Config - Store config in the environment
- Backing services - Treat backing services as attached resources
- Build, release, run - Strictly separate build and run stages
- Processes - Execute the app as one or more stateless processes
- Port binding - Export services via port binding
- Concurrency - Scale out via the process model
- Disposability - Maximize robustness with fast startup and graceful shutdown
- Dev/prod parity - Keep development, staging, and production as similar as possible
- Logs - Treat logs as event streams
- Admin processes - Run admin/management tasks as one-off processes
Tip 2: Don’t Hardcode Web Locations
During the lifecycle of your application it will be accessed via a lot of different URLs. Local access
maybe done through your normal localhost semantics, dev may have a strange URL scheme, various testing
sites along the way may have their own URL shenanigans along the way, and prod will have its own issues.
If you hardcode this into the front end
we need to build several versions of the site to release to the various environments. This is not desirable.
A better solution is to have the application be able to derive its URL schema from user-selectable sources. A common method to do this is to have it figure this out from a combination of browsed local storage and the current web page. Here’s an example from an Angular application:
// Check if there's local storage item called 'apiOverride' and use it or
// assemble the API path from the current web location
const apiLocation = localStorage.getItem('apiOverride') ||
`${window.location.protocol}//${window.location.host}${window.location.port !== '' ? ':': ''}${window.location.port}/api/`
export const environment = {
production: true,
apiLocation
};
This allows for someone to use the public code against a testing API, a testing site against, the public
API, and other combination, while also defaulting to going to http(s)://WebSiteName/api/ for the API.
Tip 3: Application Defaults Should Be Good for Dev Environments
Make your life easier. Your application’s default setting should be good for dev environments, especially local testing ones. Anything that is a feature needed only in prod, or a feature that needs to be shut off in prod, should be kept as a setting that can be passed as an environment variable, or as a compile-time setting when compiled in production mode.
Tip 4: Automate Smoke Testing
It’s better to deploy websites you know are working than to guess. To help this happen, ensure you have a runnable test suite ready that can quickly validate the operation of the site.
Modern deployment systems work to minimize switchover downtime and attempt to not make a dead site live. This is done through a variety of manners, but the two major families are:
-
Blue/Green deployments - The new site is brought on-line, automatically tested, and then put into production when it’s passing the tests.

-
Canary deployments - Both the old and new site are brought up simultaneously, and some traffic is initially sent to the new site. This amount continues to grow over time if the new site does not trigger more errors that the old site.
While Canary Deploys are wonderful, I still prefer a quick smoke-test to see if we should even bother with starting the canary deploy, so I highly recommend any application to have a set of tests ready that can quickly validate an application as ready or not ready in a few seconds.
Tip 5: Log Everything
Things will break. To diagnose, I need to see what went wrong. The following checklist should help you check if you have the right amount of logging put in:
- Log everything to stdout.
- If you can, log as JSON with defined fields.
- Ensure that debug messages can be turned off for production.
- Make sure you handle errors and post useful information that will help diagnose the issue
- Because you ignored the previous warning, have an all-purpose crash handler that dumps whatever diagnostic information would be helpful if your application crashes.
- Log anything that will cause important changes to application state, or a client/tenant’s state.
This type of logging is great for diagnosing consistent issues caused by bugs, but doesn’t really help with performance tuning or intermittent errors.
For those, it’s best to have some type of tracing like Dynatrace, or AWS’s X-Ray in place to provide more detailed trace info. Any solution for tracing will need a few things for you to keep in mind:
- A good dashboard to look and analyze the results
- Variable sampling frequencies. Normally, places capture one out of 100-10k requests for analysis, but if something bad has happened, you might want to bump that up to better capture issues
Conclusions
Hope this provided sufficient guidance on how to get your code production-ready. Please comment on the YouTube video if you have any questions.